Chapter 5 Checking for Robustness
Once you have assessed and potentially improved the computational reproducibility of the display items for a claim within a paper, you can determine these results’ robustness by modifying some analytic choices and reporting their subsequent effects on the estimates of interest, i.e., conducting robustness checks. The universe of robustness checks can be very large (potentially infinite!) and pertain to data analysis and data cleaning. The SSRP distinguishes between reasonable and feasible robustness checks.
Reasonable robustness checks (Simonsohn et. al., 2018) are (i) sensible tests of the research question, (ii) expected to be statistically valid, and (iii) not redundant with other specifications in the set. The set of feasible robustness checks is defined by all the specifications that can be computationally reproduced. We assume that the specifications already published in the paper are part of the set of reasonable specifications.
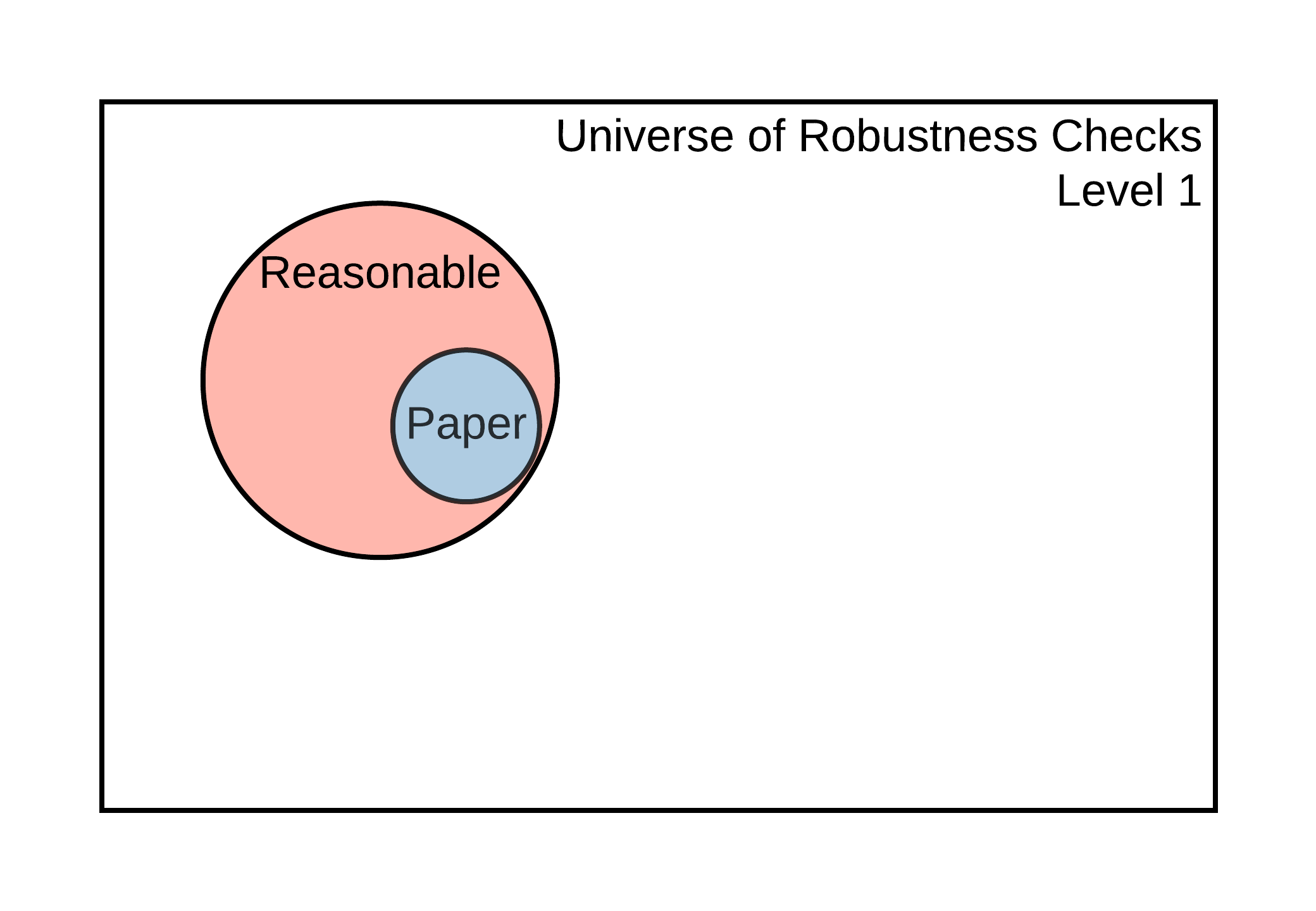
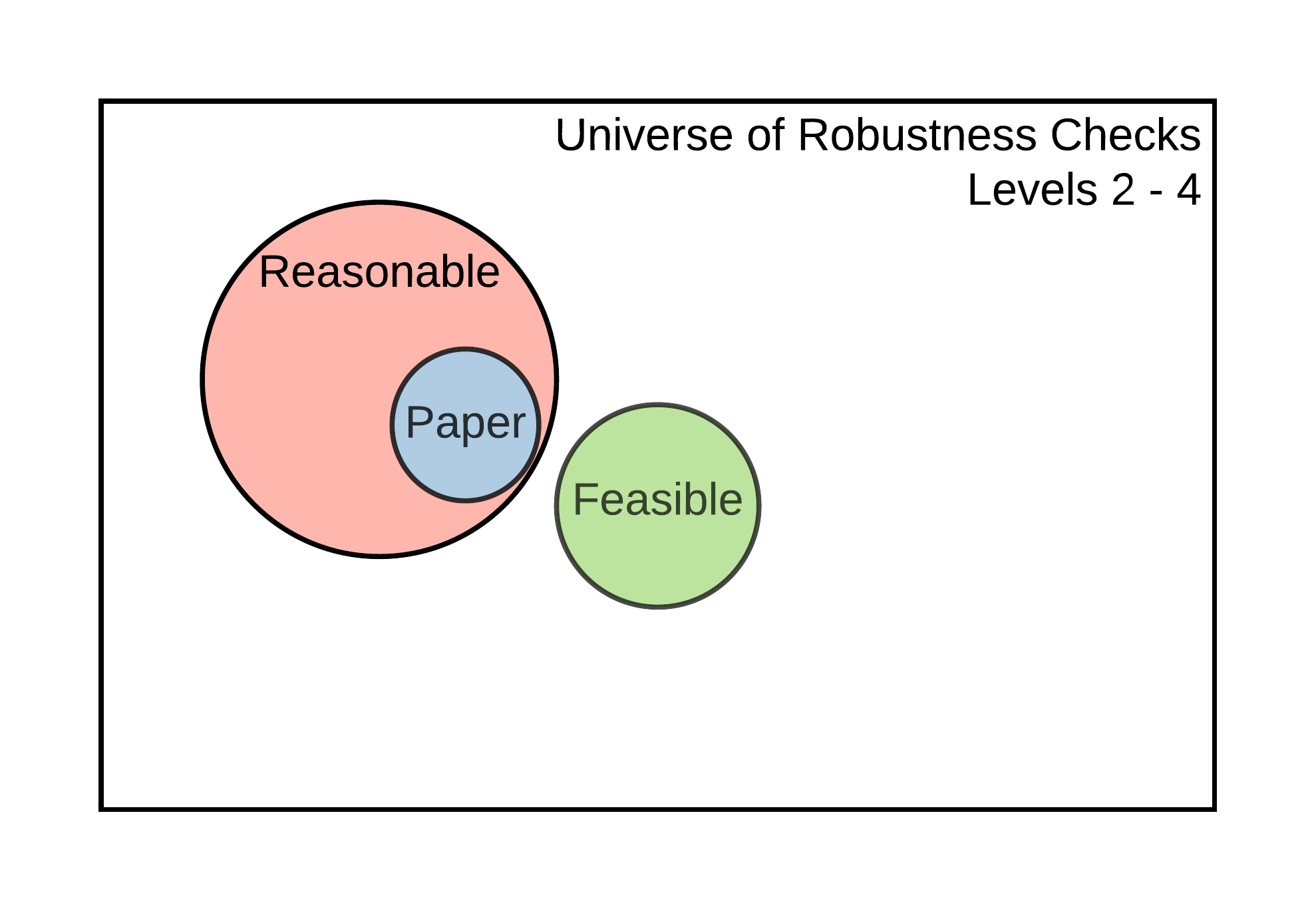
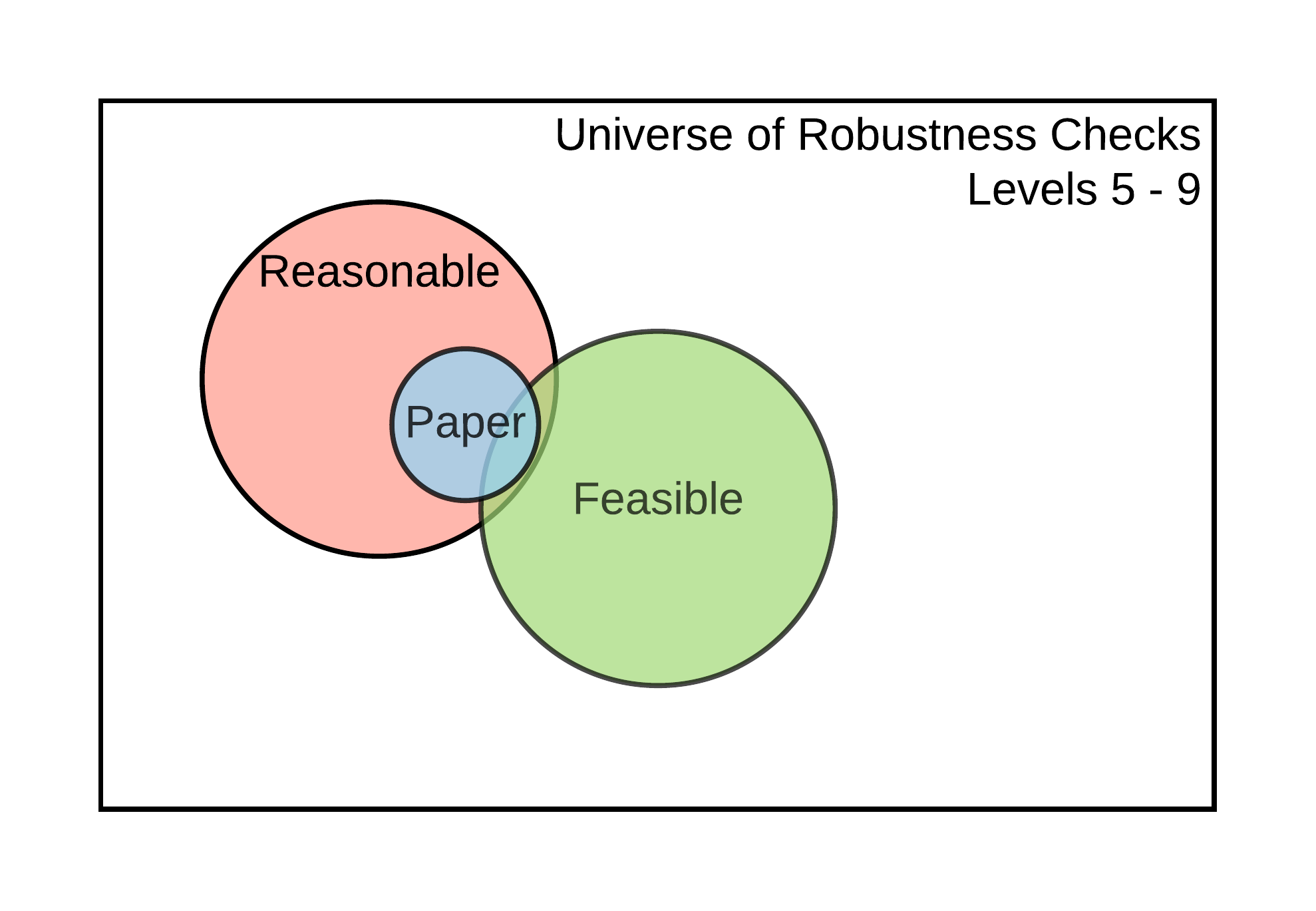
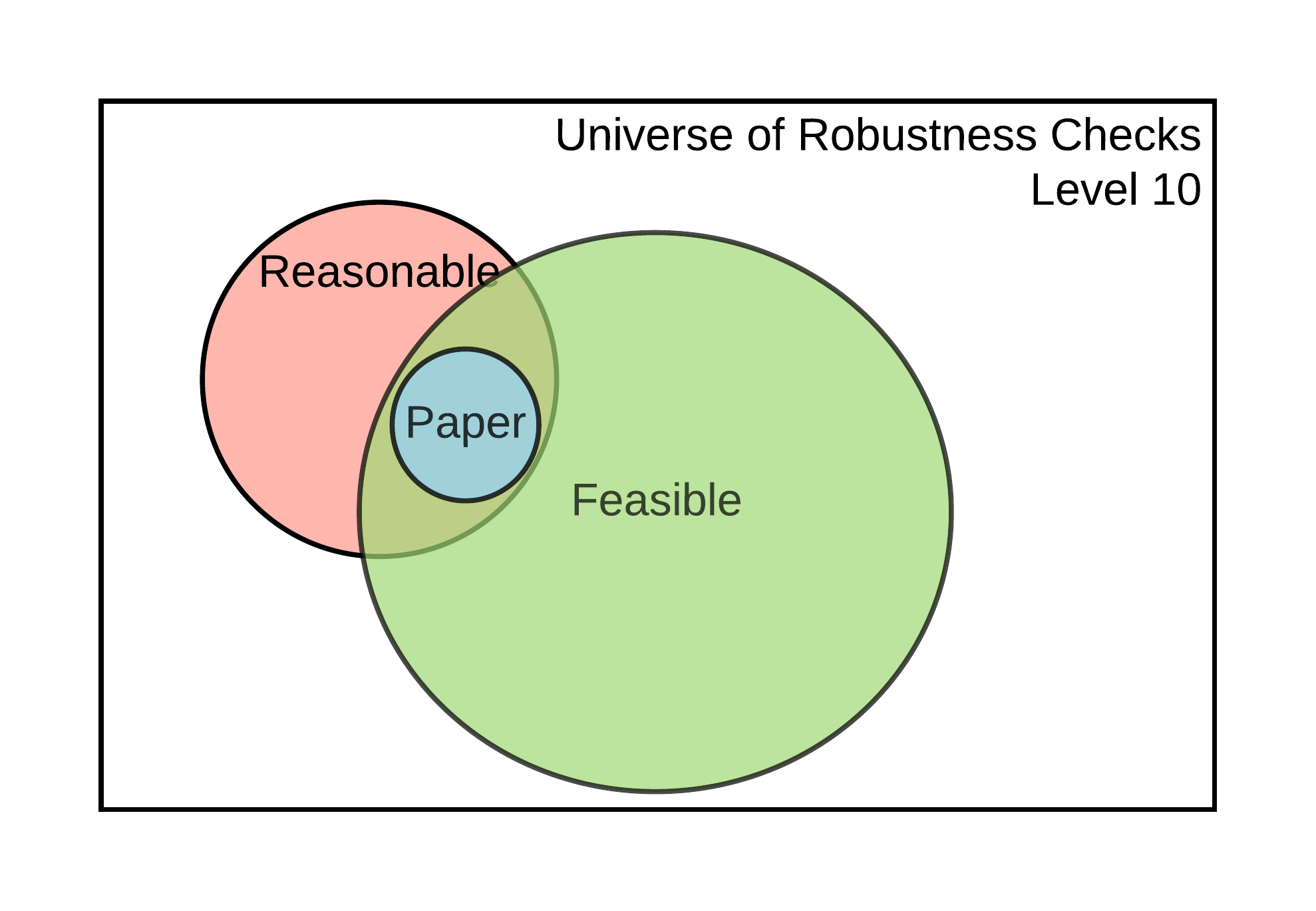
Figure 5.1: Universe of robustness tests and its elements
The size of the set of feasible robustness checks, and the likelihood that it contains reasonable specifications, will depend on the current level of reproducibility of the results that support a claim. The idea is illustrated in Figure 5.1. At Levels 1-2, it is impossible to perform additional robustness checks because there are no data to work with. It may be possible to perform additional robustness checks for claims supported by display items reproducible at Levels 3-4, but not using the estimates declared in Scoping (because the display items are not computationally reproducible from analysis data). It is possible to conduct additional robustness checks to validate the core conclusions of a claim based on a display item reproducible at Level 5. Finally, claims associated with display items reproducible at Level 6 or higher allow for robustness checks that involve data cleaning, like variable definitions and other types of analytical choices, available only from the raw data.
The number of feasible robustness checks grows exponentially with improved reproducibility. For example, when checking the robustness of a new variable definition, you could test alternative variable definitions and changes in the estimation method using such variable.
Robustness is assessed at the claim level (see the diagram with a typical paper’s components 0.1). There may be several specifications presented in the paper for a given claim, one of which the authors (or you, if the authors did not indicate) have chosen as the main or preferred specification. Identify which display item contains this specification and refer to the reproduction tree to identify the code files in which you can modify a computational choice. Using the example tree discussed in the Assessment stage, we can obtain the following (we removed the data files for simplicity). This simplified tree provides a list of potential files in which you can test different specifications:
table1.tex (contains preferred specification of a given claim)
|___[code] analysis.R
|___[code] final_merge.do
|___[code] clean_merged_1_2.do
| |___[code] merge_1_2.do
| |___[code] clean_raw_1.py
| |___[code] clean_raw_2.py
|___[code] clean_merged_3_4.do
|___[code] merge_3_4.do
|___[code] clean_raw_3.py
|___[code] clean_raw_4.pyHere we suggest two types of contributions to robustness checks: (1) increasing the number of feasible robustness checks by identifying key analytical choices in code scripts and (2) justifying and testing reasonable specifications within the set of feasible checks. Both contributions should be recorded on the SSRP Platform and be linked to specific files in the reproduction package.
5.1 Feasible robustness checks: increasing the number of feasible specifications
Increasing the number of feasible robustness checks requires identifying the specific line(s) in the code scripts that execute an analytical choice. An advantage of this type of contribution is that you don’t need to have an in-depth knowledge of the paper and its methodology to contribute. This allows you to potentially map several code files, achieve a broader understanding of the paper, and build on top of others’ work. The disadvantage is that you are not expected to test and justify the reasonableness of alternative specifications.
Analytical choices can include those behind data cleaning and data analysis. Below are some proposed types for each category.
Analytical choices in data cleaning code
- Variable definition
- Data sub-setting
- Data re-shaping (merge, append, long/gather, wide/spread)
- Others (specify as “processing - other”)
Analytical choices in analysis code
- Regression function (link function)
- Key parameters (tuning, tolerance parameters, and others)
- Controls
- Adjustment of standard errors
- Choice of weights
- Treatment of missing values
- Imputations
- Other (specify as “methods - other”)
To record a specific analytical choice on the SSRP, please follow these steps:
Review a specific code file (e.g.
clean_merged_1_2.do) and identify an analytical choice (e.g.regress y x if gender == 1).Record the file name, line number, choice type, and choice value, as they appear in the original reproduction package. Sometimes the same analytical choice will be used more than one time in a fiven analysis (for example, a specific set of covariates is repeated across multiple regressions). In the
sourcefield, type “original” whenever the analytical choice is identified for the first time, andfile name-L+line numbereach time the same analytical choice is applied thereafter (for example, if an analytical choice is identified for the first time in line #103 and for the second time in line #122 their respective values for thesourcefield should beoriginal,code_01.do-L103, andcode_01.do-L103respectively). For each analytical choice recorded, add the specific choice used in the paper and, optionally, describe what alternatives could have been used in thechoice_rangecolumn (e.g., “min, max” or “alt 1, alt 2, alt 3”). The resulting database would look like this (real reproduction example here):
| entry_id | file_name | line_number | choice_type | choice_value | choice_range | source |
|---|---|---|---|---|---|---|
| 1 | code_01.do | 73 | data sub-setting | males | males, female | original |
| 2 | code_01.do | 122 | variable definition | income = wages + capital gains | wages, capital gains, gifts | code_01.do-L103 |
| 3 | code_05.R | 143 | controls | age, income, education | age, income, education, region | original |
| … | … | … | … | … | … | … |
The process of recording analytical choices can take a long time. Here a reproducer is not expected to identify all analytical choices. Ideally reproducers will focus on one script and map as much as possible within that script. Reproducers are encouraged to build on top of previous reproductions by exporting analytical choices of previous reproducers (by searching into previous reproductions and clicking “download table as csv” in the robustness section) and uploading them into their own reproduction (by clicking “upload csv”).
5.2 Justifying and testing reasonable robustness checks
Justifying and testing a specific robustness check involves identifying one or more feasible analytical choices, conducting a variation on them, and justifying its reasonableness. This approach’s advantage is that it allows for an in-depth inspection of a specific section of the paper. Its main limitation is that justifying sensibility and validity (and non-redundancy, to an extent) requires a deeper understanding of the paper’s topic and the methods. That may mean that undergraduate students or graduate students with only a surface-level interest in the paper (or limited time) may find it challenging to conduct this part of the reproduction.
When performing a specific robustness check, follow these steps:
- Identify the set of analytical choices you will modify for a specific robustness test. Record the identifier(s) corresponding to the analytical choice(s) of interest (
entry_id). For multiple identifiers, separate them using comma (e.g.,entry_id= 2, 5, 7).
Propose a specific variation to these set of analytical choices.
Discuss whether you think these variations are sensible, specifically in the context of the claim tested (e.g., does it make sense to include or exclude low-income Hispanic people from the sample when assessing the impact of a large wave of new immigrants?).
Discuss how these variations could affect the validity of the results (e.g., likely effects on the omitted variable bias, measurement error, change in the Local Average Treatment Effects for the underlying population).
Confirm that this test is not redundant with other tests in the paper or in the robustness exercise.
Report the result of the robustness check (new estimate, standard error, and units), and discuss differences with the pre-specified estimates for this claim.
Discussing the reasonableness of a new robustness check could benefit from an open exchange of ideas. We recommend that reproducers create a new entry in the SSRP forum (remember to tag the DOI of the paper so others can find it) and post their robustness section in the forum to discuss with others (once public and in view only, you can share a link to any specific section of your reproduction).