Introduction
Computational reproducibility is the degree to which it is possible to obtain consistent results using the same input data, computational methods, and conditions of analysis (National Academies of Sciences 2019). In 2019, the American Economic Association updated its Data and Code Availability Policy to require that the AEA Data Editor verify the reproducibility of all papers before they are accepted by an AEA journal. Similar policies have been adopted in political science, particularly at the American Journal of Political Science. In addition to the requirements laid out in such policies, the data editors of several social science journals produced detailed recommendations and resources to facilitate compliance. The goal of such policy changes is to improve the computational reproducibility of all published research going forward, after several studies showed that rates of computational reproducibility in the social sciences range from somewhat low to alarmingly low (Galiani, Gertler, and Romero 2018; Chang and Li 2015; Kingi et al. 2018).
This Guide includes a common approach, terminology, and standards for conducting reproductions, or attempts to assess and improve the computational reproducibility of published work. At the center of this process is the reproducer (you!), a party rarely involved in the production of the original paper. Reproductions sometimes involve the original author (whom we refer to as “the author”) in cases where additional guidance and materials are needed to execute the process. Reproductions should be distinguished from replications, where replicators re-examine a study’s hypotheses using different data or different methods (or both) (King 1995). We find that reproducibility is necessary for replicability, though both allow science to be “self-correcting.”
We recommend using this Guide in conjunction with the Social Science Reproduction Platform (SSRP), an open-source platform that crowdsources and catalogs attempts to assess and improve the computational reproducibility of published social science research. Though in its current version, the Guide is primarily intended for reproductions in economics, it may be used in other social science disciplines, and we welcome contributions that aim to “translate” any of its parts to other social science disciplines (learn how you can contribute here). Find definitions of fundamental concepts in reproducibility and the process of conducting reproductions in the Glossary chapter.
This Guide and the SSRP were developed as part of the Accelerating Computational Reproducibility (ACRe) project, which aims to assess, enable, and improve the computational reproducibility of published social science research. The ACRe project is led by the Berkeley Initiative for Transparency in the Social Sciences (BITSS)—an initiative of the Center for Effective Global Action (CEGA)—and Dr. Lars Vilhuber, Data Editor for the journals of the American Economic Association (AEA). This project is supported by Arnold Ventures.
View slides used for the presentation “How to Teach Reproducibility in Classwork”
Beyond binary judgments
Assessments of reproducibility can easily gravitate towards binary judgments that declare an entire paper as “(ir-)reproducible”. We suggest a more nuanced approach based on two observations that make binary judgments less relevant.
First, a paper may contain several scientific claims (or major hypotheses) that may vary in computational reproducibility. Each claim is tested using different methodologies, presenting results in one or more display items (outputs like tables and figures). Each display item will itself contain several specifications. Figure 0.1 illustrates this idea.
Figure 0.1: One paper has multiple components to reproduce.
DI: Display Item, S: Specification
Second, for any given specification, there are several reproducibility levels, ranging from the absence of any materials to complete reproducibility starting from raw data. Moreover, even for a specific claim-specification combination, distinguishing the appropriate level can be far more constructive than simply labeling it as (ir-)reproducible.
Note that the highest level of reproducibility, which requires complete reproducibility starting from raw data, is very demanding and should not be expected of all published research — especially before 2019. Instead, this level can serve as an aspiration for social science research, as we look to improve the reproducibility of research and facilitate the transmission of knowledge throughout the scientific community.
Reproduction stages
Reproductions can be divided into five stages, corresponding to the first five chapters of this guide:
- Paper selection, where you will select a candidate paper and try to locate its reproduction package. If a reproduction package is available, you will declare the paper and start the reproduction, or select a new candidate paper (after leaving a record on the SSRP);
- Scoping, where you will define the scope of the exercise by recording the claims, display items, and specifications you will focus on in the remainder of the reproduction;
- Assessment, where you will review and describe in detail the available reproduction package and assess the current level of computational reproducibility of the selected display items;
- Improvement, where you will modify the content and/or the organization of the reproduction package to improve its reproducibility;
- Robustness, where you will identify analytical choices to increase the number of feasible robustness checks, and/or you will justify the reasonableness of a specific robustness check.
This Guide does not include a possible fifth stage of extension, where you may extend the current paper by including new methodologies or data, which would bring the exercise closer to a replication.

Figure 0.2: Four stages of a reproduction attempt
The order of the stages may not be chronologically linear. For example, you may realize that the scope of a reproduction is too ambitious and switch to a less intensive one. Later in the exercise, you can also begin testing different specifications for robustness while also assessing the paper’s reproducibility level. The only stage that should go first, and cannot be edited once finished, is the Scoping stage.
Different stages in the reproduction process correspond to different units of analysis (see Figure 0.3 for an overview). The Scoping stage will focus on scientific claims selected for reproduction. Once you specify your claims of interest, in the Assessment and Improvement stages you will focus on the display items associated with those claims. In the Robustness stage, claims are once again the unit of analysis.
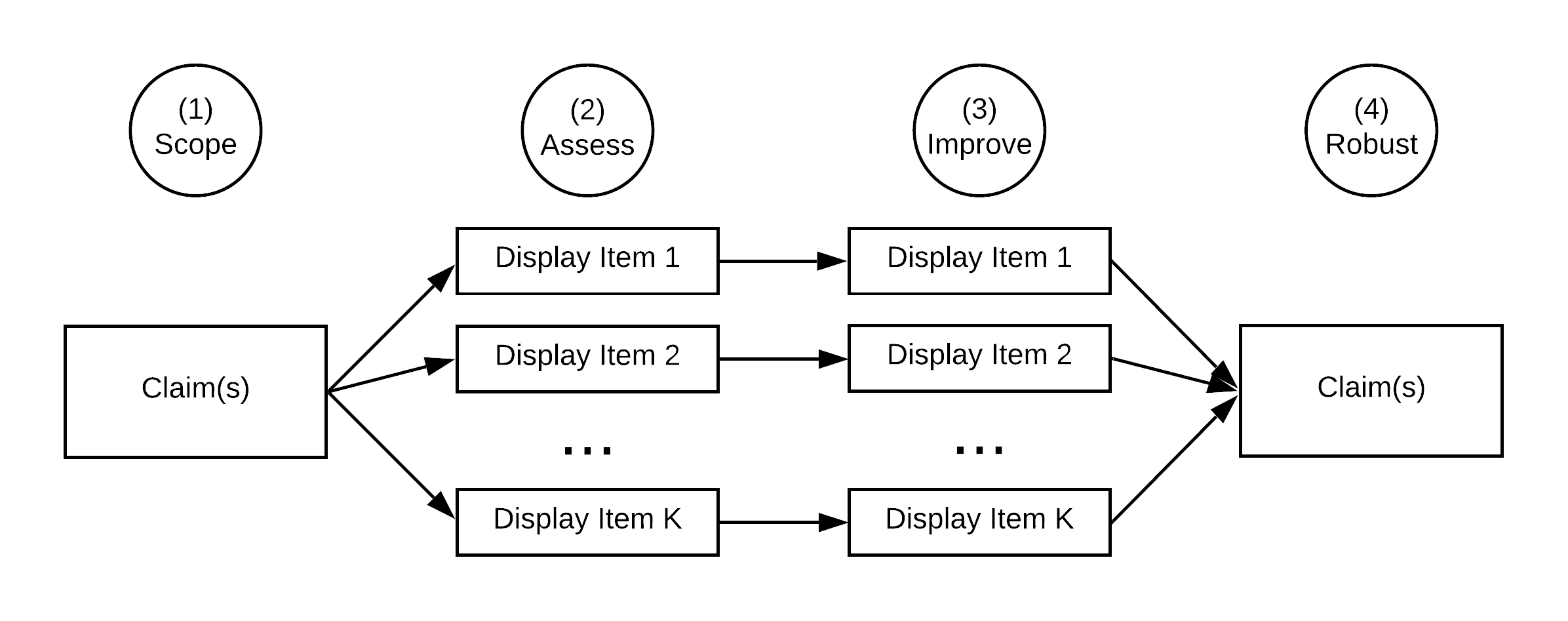
Figure 0.3: Relevant unit of analysis at each stage of a reproduction attempt
Reproduction strategies
In most cases, you will begin a reproduction with a thorough reading of your paper of interest. However, the sequence of the steps you take in the remainder of the reproduction may follow various reproduction strategies. The most obvious strategy would be to follow the order of the steps as outlined above. You may also first choose one of the paper’s many claims and then focus on assessing and improving the reproduction package accordingly. Using an alternative strategy, you might identify potential robustness checks or extensions while reading the paper and then focus only on the results associated with that robustness check. In another strategy, you may identify a paper that uses a particular dataset in which you are interested and then only reproduce or conduct robustness checks for the results associated with that dataset.